Chapter 4 Classification Example
4.1 Background & Data
In this section, we shift away from regression BART models and demonstrate how to fit a BART model for classification purpose. We aim to make use of the palmerpenguins dataset to build a BART model to predict what species a penguin is out of three different observed options: Adelie, Chinstrap, and Gentoo based on their various traits.
These data were collected from 2007 to 2009 by Dr. Kristen Gorman with the Palmer Station Long Term Ecological Research Program, which is part of the US Long Term Ecological Research Network. The data were imported directly from the Environmental Data Initiative (EDI) Data Portal, and are available for use by CC0 license (“No Rights Reserved”) in accordance with the Palmer Station Data Policy.
# Load packages
library(tidyverse)
library(tidymodels)
library(ggplot2)
library(countrycode)
library(plotly)
library(sysfonts)
library(showtext)
library(glue)
library(scales)
library(janitor)
library(DALEXtra)
library(dbarts)
# Loading data
# install.packages("palmerpenguins")
library(palmerpenguins)
data(penguins)
head(penguins)
## # A tibble: 6 × 8
## species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
## <fct> <fct> <dbl> <dbl> <int> <int>
## 1 Adelie Torgersen 39.1 18.7 181 3750
## 2 Adelie Torgersen 39.5 17.4 186 3800
## 3 Adelie Torgersen 40.3 18 195 3250
## 4 Adelie Torgersen NA NA NA NA
## 5 Adelie Torgersen 36.7 19.3 193 3450
## 6 Adelie Torgersen 39.3 20.6 190 3650
## # ℹ 2 more variables: sex <fct>, year <int>4.3 Implementation
4.3.1 dbarts package
Now we will fit the model in a similar way to the regression model as described in the last chapter, except now with our penguin data specifications. We are using the variables for bill length, bill depth, flipper length, and body mass of the penguins to predict their species. We can view some examples of trees within the model as well.
# Fitting a BART model with 200 trees with 1000 iterations
set.seed(4343)
p.bartFit <- bart(x.train = as.matrix(penguin_train[,3:6]), y.train = as.numeric(unlist(penguin_train[,1])), keeptrees = TRUE, ndpost = 1000)
##
## Running BART with numeric y
##
## number of trees: 200
## number of chains: 1, number of threads 1
## tree thinning rate: 1
## Prior:
## k prior fixed to 2.000000
## degrees of freedom in sigma prior: 3.000000
## quantile in sigma prior: 0.900000
## scale in sigma prior: 0.003171
## power and base for tree prior: 2.000000 0.950000
## use quantiles for rule cut points: false
## proposal probabilities: birth/death 0.50, swap 0.10, change 0.40; birth 0.50
## data:
## number of training observations: 249
## number of test observations: 0
## number of explanatory variables: 4
## init sigma: 0.255188, curr sigma: 0.255188
##
## Cutoff rules c in x<=c vs x>c
## Number of cutoffs: (var: number of possible c):
## (1: 100) (2: 100) (3: 100) (4: 100)
## Running mcmc loop:
## iteration: 100 (of 1000)
## iteration: 200 (of 1000)
## iteration: 300 (of 1000)
## iteration: 400 (of 1000)
## iteration: 500 (of 1000)
## iteration: 600 (of 1000)
## iteration: 700 (of 1000)
## iteration: 800 (of 1000)
## iteration: 900 (of 1000)
## iteration: 1000 (of 1000)
## total seconds in loop: 0.477895
##
## Tree sizes, last iteration:
## [1] 2 2 2 2 1 2 3 2 2 2 2 2 2 5 2 2 2 1
## 3 4 2 3 2 2 2 2 3 3 3 2 3 3 3 2 1 2 2 2
## 2 4 2 2 3 1 2 3 1 2 4 2 3 3 6 3 2 2 2 2
## 3 2 3 3 2 2 5 2 2 2 2 3 2 2 2 3 2 1 2 1
## 2 2 2 2 3 4 4 2 2 4 3 3 3 3 2 2 2 4 3 2
## 3 2 2 2 2 2 2 2 3 2 2 3 4 3 2 3 3 3 2 3
## 2 5 3 3 1 2 2 2 1 2 2 3 2 4 1 2 2 2 3 2
## 4 2 1 3 2 2 3 3 2 3 2 2 3 3 2 2 1 3 2 3
## 2 2 2 3 2 3 2 2 2 1 2 2 3 3 2 3 3 3 2 2
## 2 2 2 2 3 2 3 2 2 2 2 2 2 4 2 1 2 2 2 2
## 2 2
##
## Variable Usage, last iteration (var:count):
## (1: 69) (2: 86) (3: 69) (4: 51)
## DONE BART
trees <- extract(p.bartFit, "trees")
# Looking at some examples of trees from model
p.bartFit$fit$plotTree(chainNum = 1, sampleNum = 3, treeNum = 112)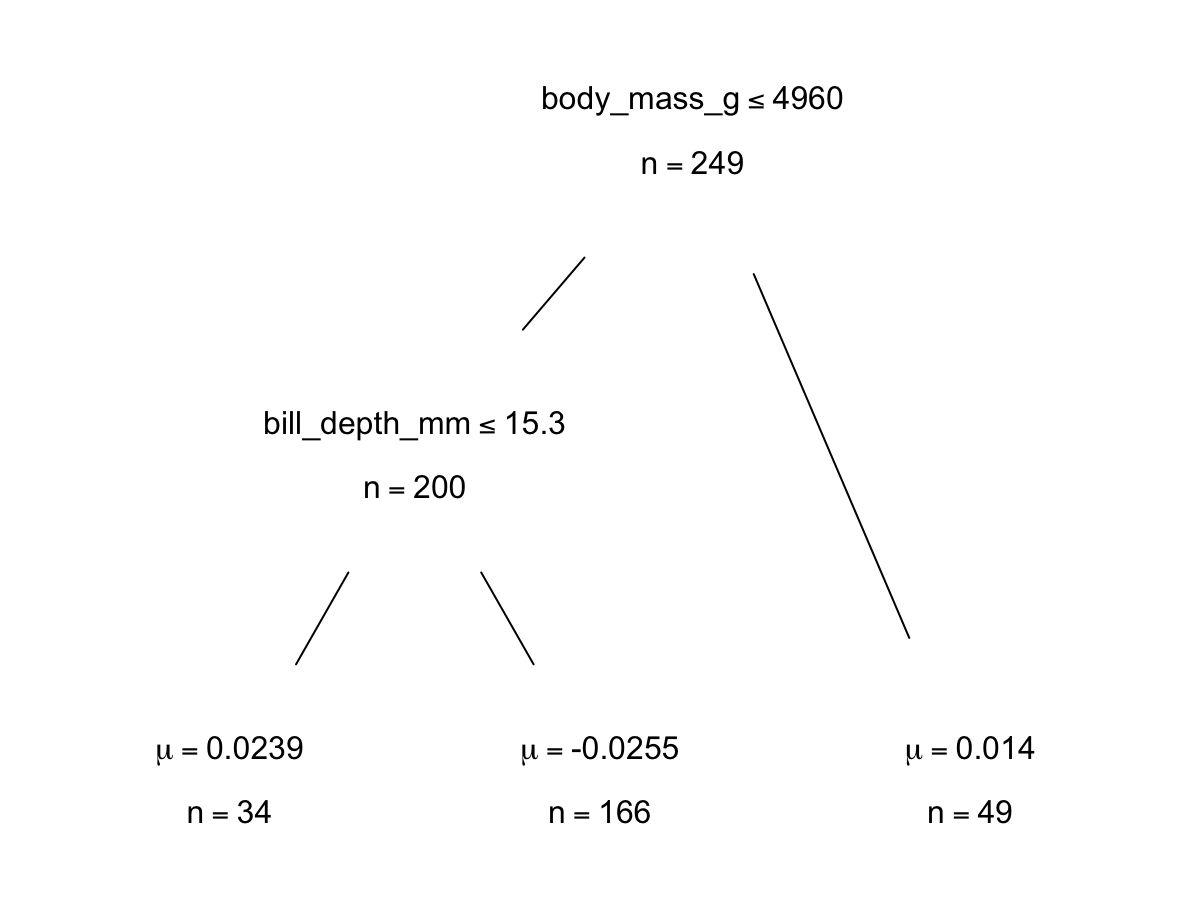
4.3.2 bartMan package
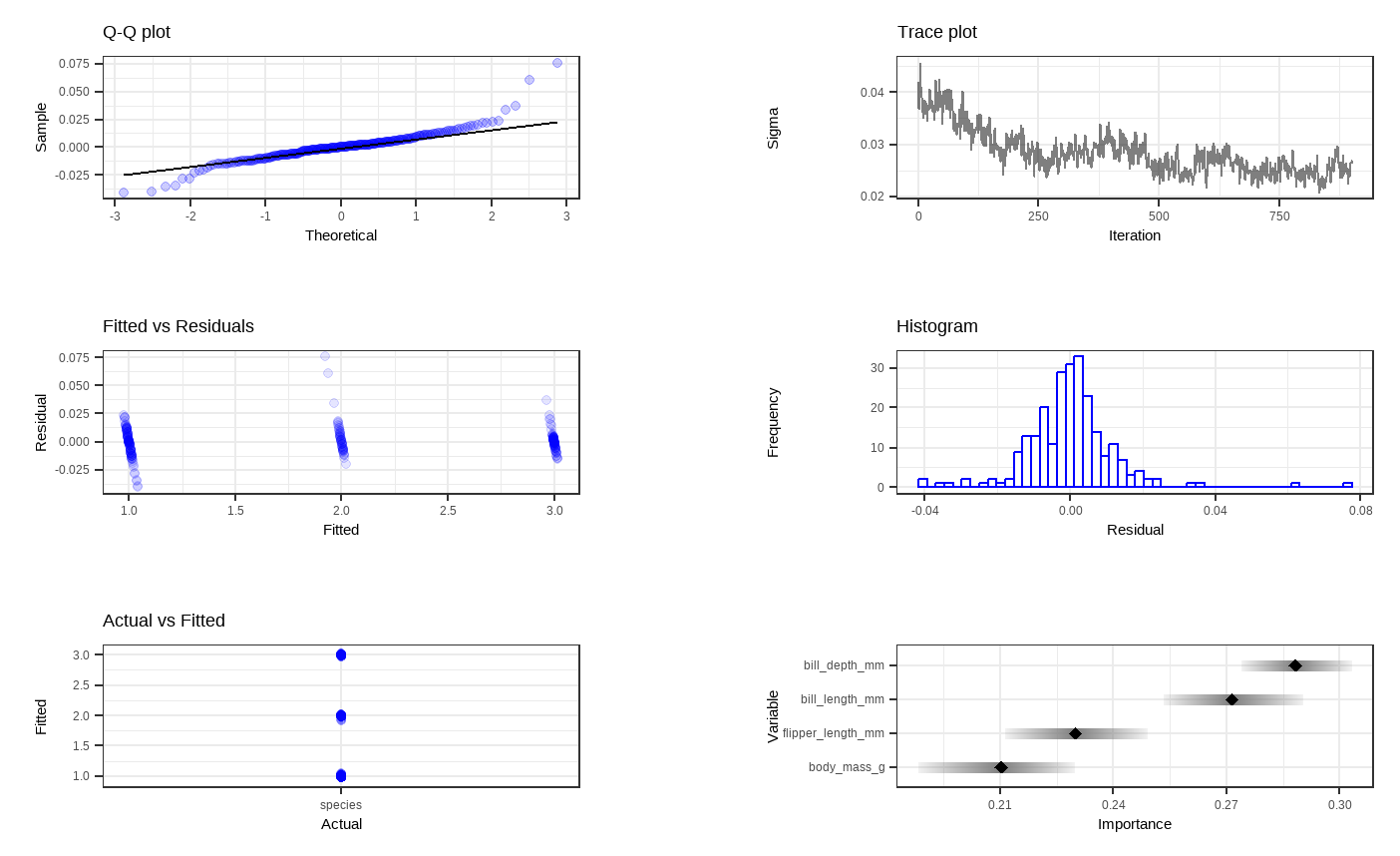
Shown above are six general diagnostic plots for the BART regression fit on our dataset. Top left: A QQ-plot of the residuals after fitting the model. Top right: trace plot of \(\sigma\) from MCMC iteration. Middle left: Residuals versus fitted values with 95% credible intervals. Middle right: A histogram of the residuals. Bottom Left: Actual values versus fitted values with 95% credible intervals. (This is unfornately not working properly due to unknown reasons). Bottom right: Variable importance plot with 25 to 75% quantile interval shown. In our case, the BART model decides that the body mass variable is the least important to predict penguin species.
Then, we want to visualize all the trees we fitted across all iterations. For less computational time and simplicity, we reduce the number of trees as well as the number of iterations for each tree. With dbarts, we fit a new model with the same variables with 50 trees for 10 iterations.
# Fitting another BART model with fewer trees and less iterations
set.seed(4343)
p.bartFit50 <- bart(x.train = as.matrix(penguin_train[,3:6]), y.train = as.numeric(unlist(penguin_train[,1])), keeptrees = TRUE, ntree = 50, ndpost = 10, verbose = FALSE) # Extracting the tree data
p.trees_data <- extractTreeData(p.bartFit50, penguins)
# Visualizing what each of the 50 trees look like over their 10 iterations
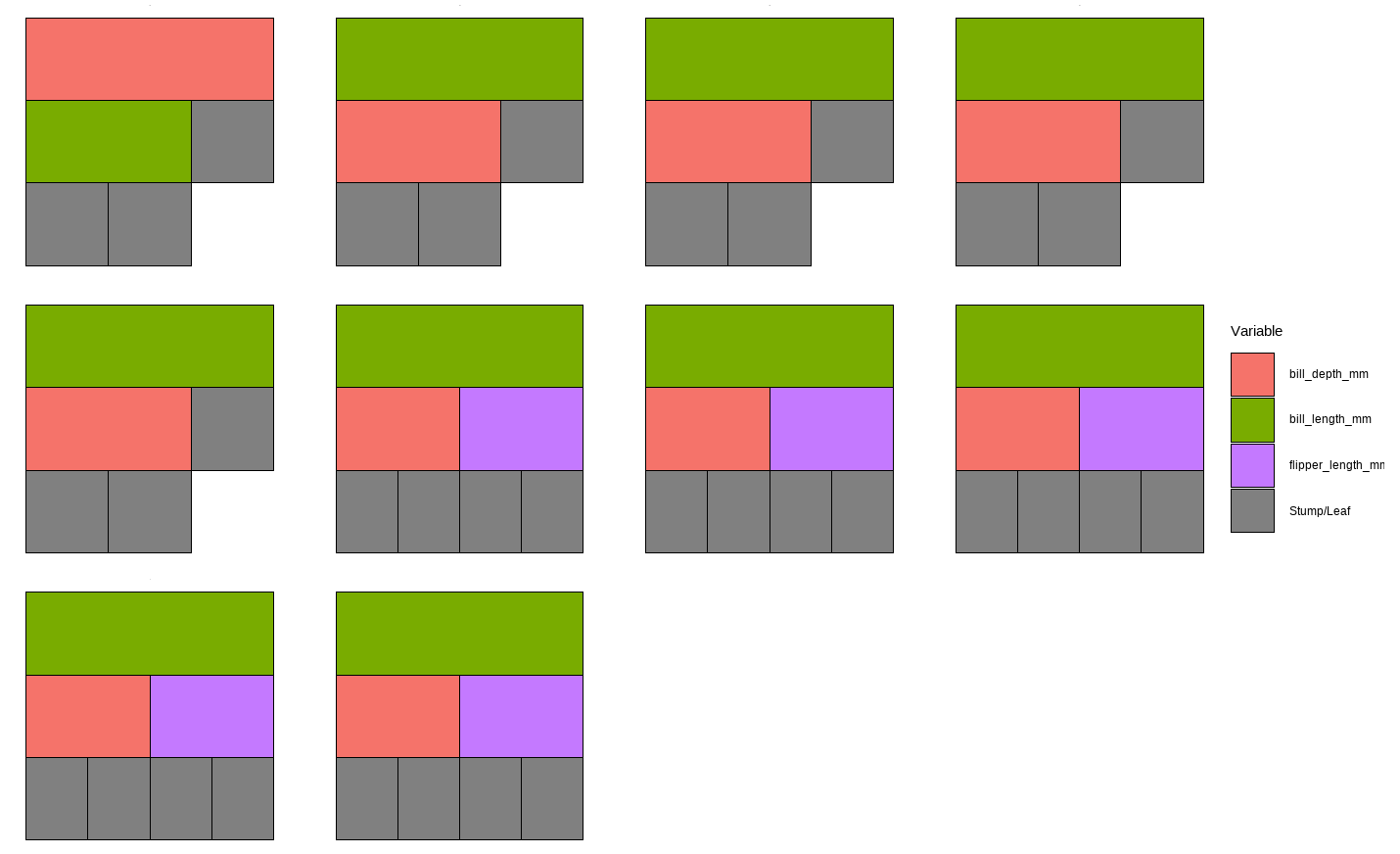
plotTrees(trees = p.trees_data, fillBy = NULL, sizeNodes = TRUE)
In the plot above, each little box represents a single tree. There are 500 boxes, thus 500 = 50 \(\cdot\) 10 trees, because it is showing all the trees (50 trees) built in all iterations after the burn-in period (10 iterations) in the reduced model. Different colors represent different variables that a tree is splitting on, and the gray represents a stump/leaf, or a terminal node.
While this plot is useful, it is hard to get insight from it because that is too much to look at at one time. To deal with that, we can specify one tree to look at all the iterations (10) of it. Here we are using the \(13^{th}\) as an example:
However, that is only the information of one tree. An even better alternative to grab information efficiently is to use the treeBarPlot function in the bartMan package. This function creates a bar plot that shows how many times each specific structure of tree, including which variable the tree splits on (but not its splitting rule value), shows up within the model. We also create a density plot that shows the splitting variables and the frequency at which each splitting rule value is chosen.
# Creating bar plot showing frequency of 10 most common trees from model
treeBarPlot(p.trees_data, iter = NULL, topTrees = 10, removeStump = FALSE)
# Creating density plot of variable split levels values
splitDensity(trees = p.trees_data, data = df_tidy, display = 'ridge')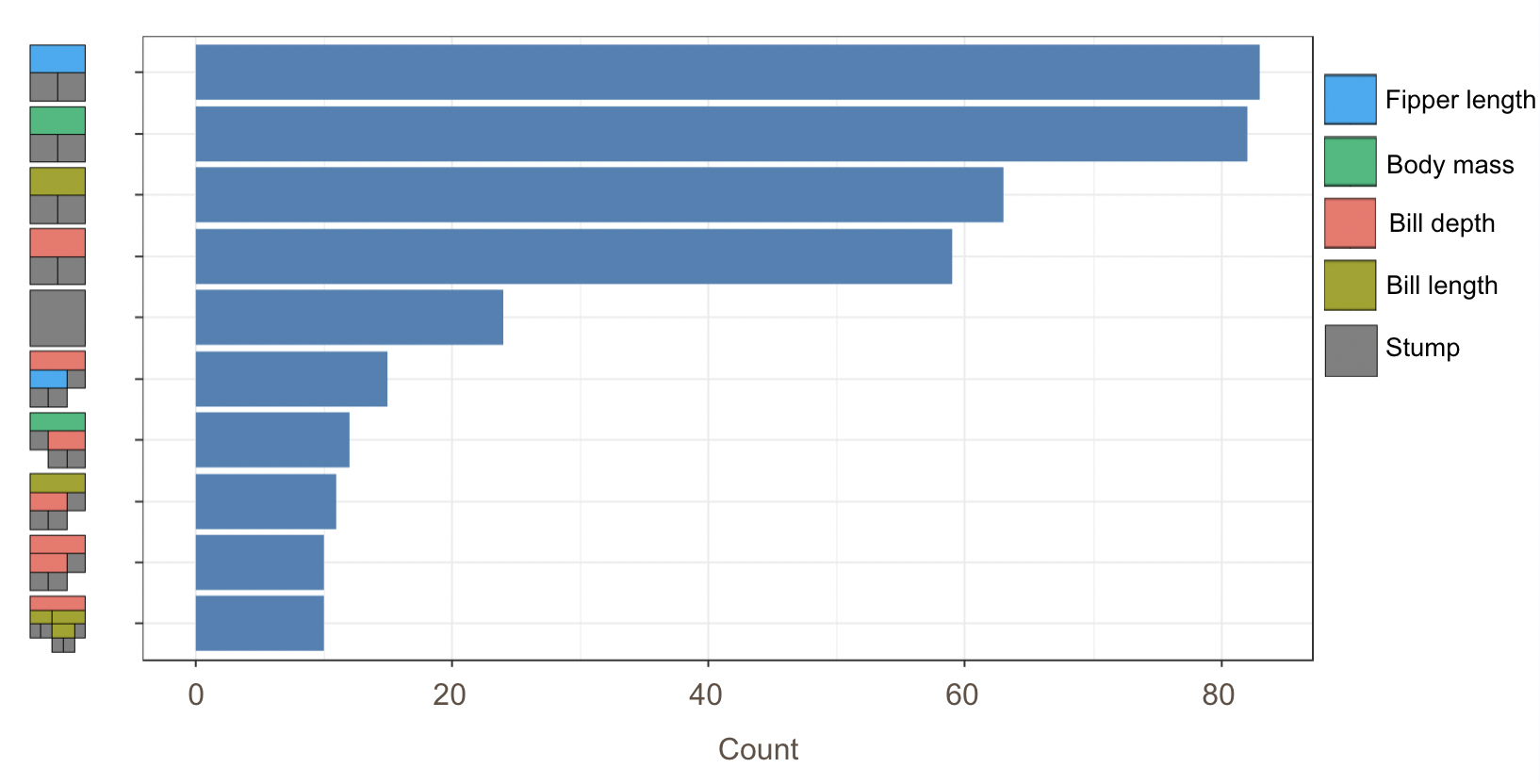
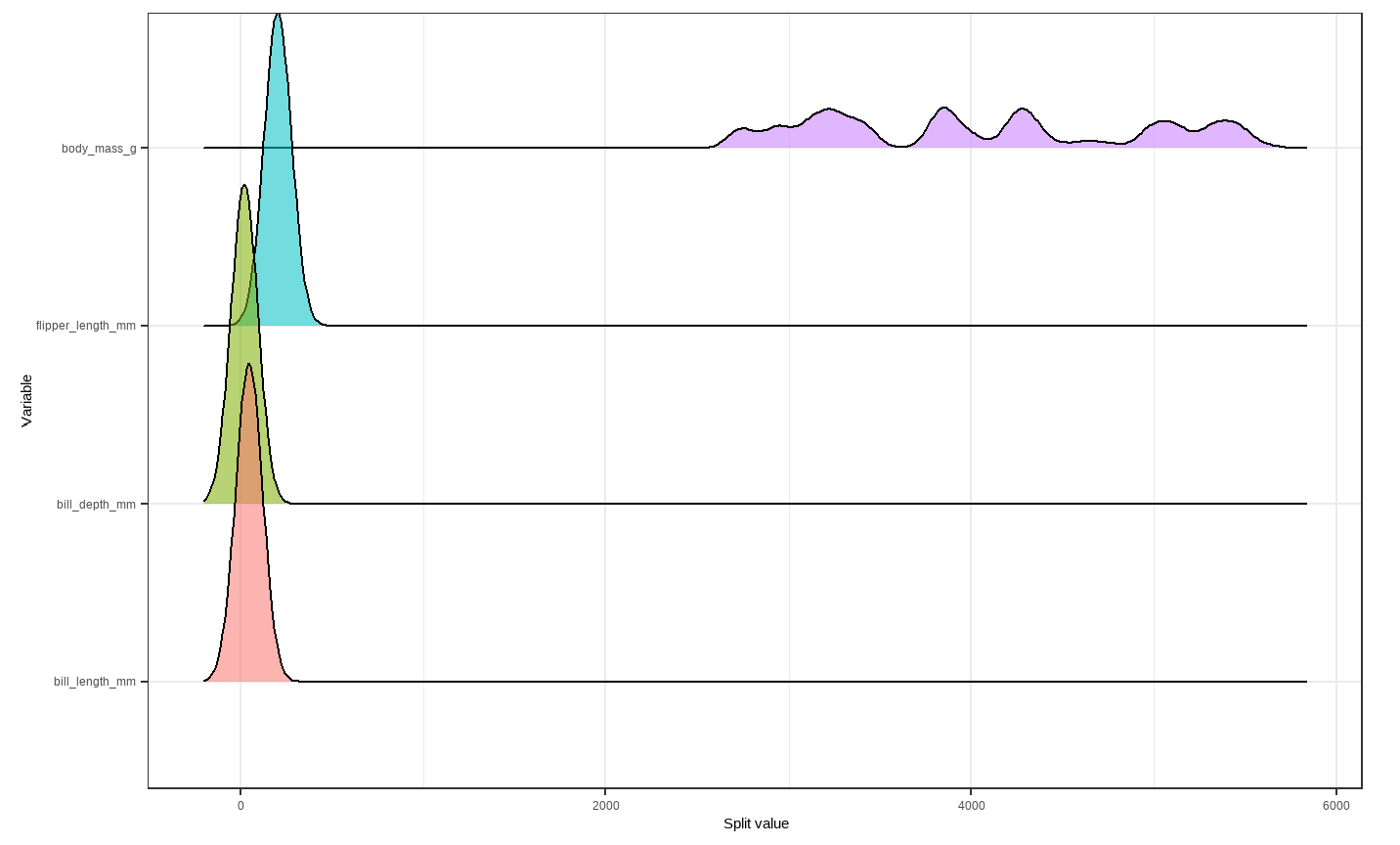
Note: These visuals can be interesting to look at and interpret, but there is a discrepancy in the colors that are shown between the 500-tree plot, the density plot, and the bar plot. There is no legend argument for the treeBarPlot, so we manually added in the legends for these later plots. We made sure that the variables match the colors as described in the legend by checking original code of the function treeBarPlot.
4.3.3 tidymodels package
Next, we decide to use the tidymodels package to fit our BART model and assess its overall performance. This is because tidymodels is more comprehensive and provides an standardized workflow for not only training and testing the model, but also performing cross-validation on the model. The steps for this package are universal for machine learning in R.
When we are fitting our model using tidymodels, we use a very similar layout to the code from our regression model in the last chapter. However, we need to change the mode to classification rather than regression and change to classification evaluation metrics. Using the bottom-right diagnostic plot from the dbarts model, we decide to take out the body mass variable to fit our new BART model with tidymodels.
#Preprocessing
penguin_rec <- recipe(species ~ bill_length_mm + bill_depth_mm + flipper_length_mm , data = penguin_train)
#Modeling with BART
penguin_spec <-
parsnip::bart() %>%
set_engine("dbarts") %>%
set_mode("classification")
#Workflow
penguin_wf <-
workflow() %>%
add_recipe(penguin_rec) %>%
add_model(penguin_spec)
#cross-validation for resamples
set.seed(12345)
penguin_folds <- vfold_cv(penguin_train)
classification_metrics <- metric_set(accuracy)
# Resampling for the classification metrics
penguin_rs <-
penguin_wf %>%
fit_resamples(resamples = penguin_folds, metrics = classification_metrics)
# Compute the classification metrics
collect_metrics(penguin_rs)
## # A tibble: 1 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.642 10 0.0211 Preprocessor1_Model1The accuracy of this model shows that our model correctly classifies species of penguin 64% of the time.
In our methodology chapter, we discussed BART probit, which is specifically for binary outputs. Thus, we fit a model that takes the same set of attributes to predict penguins’ sex.
#Preprocessing
penguin_rec <- recipe(sex ~ bill_length_mm + bill_depth_mm+ flipper_length_mm, data = penguin_train)
#Modeling with BART
penguin_spec <-
parsnip::bart() %>%
set_engine("dbarts") %>%
set_mode("classification")
#Workflow
penguin_wf <-
workflow() %>%
add_recipe(penguin_rec) %>%
add_model(penguin_spec)
#cross-validation for resamples
set.seed(12345)
penguin_folds <- vfold_cv(penguin_train)
classification_metrics <- metric_set(accuracy, precision)
# Resampling for the classification metrics
penguin_rs <-
penguin_wf %>%
fit_resamples(resamples = penguin_folds, metrics = classification_metrics)
# Compute the classification metrics
collect_metrics(penguin_rs)
## # A tibble: 2 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy binary 0.871 10 0.0245 Preprocessor1_Model1
## 2 precision binary 0.867 10 0.0340 Preprocessor1_Model1We are able to view both accuracy and precision estimates for this model as it has a binary response variable. From the overall accuracy, we can see that this model correctly classifies a penguin’s sex 87.1% of the time, which is pretty good.
The precision is calculated using \(\frac{\text{True Positive}}{\text{True Positive + False Positive}}\). In our context, it measures the proportion of true predictions among all female predictions. With the observed precision value, when the model predicts a penguin to be a female, it is correct about 86.7% of the time.
4.4 References
AlanInglis. (n.d.). GitHub - AlanInglis/bartMan: Visualisations for posterior evaluation of BART models. GitHub. https://github.com/AlanInglis/bartMan?tab=readme-ov-file
Bayesian additive regression trees (BART) - bart. - bart • parsnip. (n.d.). https://parsnip.tidymodels.org/reference/bart.html
Disci, S. (2022, December 8). The effect of childhood education on wealth: Modeling with bayesian additive regression trees (BART): R-bloggers. R. https://www.r-bloggers.com/2022/12/the-effect-of-childhood-education-on-wealth-modeling-with-bayesian-additive-regression-trees-bart/#google_vignette
Inglis, A., Parnell, A. C., & Hurley, C. (2024). Visualisations for Bayesian Additive Regression Trees. Journal of Data Science, Statistics, and Visualisation, 4(1). https://doi.org/10.52933/jdssv.v4i1.79
Introduction to palmerpenguins. (n.d.). https://allisonhorst.github.io/palmerpenguins/articles/intro.html
OECD (2024), Enrolment rate in early childhood education (indicator). doi: 10.1787/ce02d0f9-en (Accessed on 30 April 2024)
OECD (2024), Household net worth (indicator). doi: 10.1787/2cc2469a-en (Accessed on 30 April 2024)